PCCX™ technology / operated by Altifigence™.
This repository is the KV260 + PCCX v002 LLM application integration repo. The reusable v002 IP-core is pinned at
third_party/pccx-v002. Future v003 IP-core will live inpccx-v003.
Open SystemVerilog NPU for experimental Gemma-class LLM acceleration on AMD/Xilinx Kria KV260.
PCCX KV260 Evidence State
xsim: PASS 12/0
post-synth timing: RTL synthesis-closed (WNS 0.052)
post-impl timing recovery in progress; evidence pending
bitstream: not generated
KV260 board execution: no evidence
Gemma 3N E4B runtime: no evidence
throughput: no measurement
Current status: RTL synthesis-closed (WNS 0.052); post-impl timing recovery in progress; evidence pending.
This repo is the KV260 + PCCX v002 LLM application integration repo.
It hosts board integration, bare-metal driver source, application wiring,
and the Vivado/sim wrappers that consume the reusable pccx-v002 LLM
package through third_party/pccx-v002 and hw/vivado/filelist.v002.f.
This is not a production bitstream release. xsim and RTL synthesis evidence are present; post-impl timing recovery, bitstream generation, board execution, and full Gemma 3N E4B application wiring remain in progress or pending.
The design rationale, ISA, memory map, and model-mapping notes live on the pccx documentation site. This repo implements what that site specifies — read the spec first, then come back here for the KV260 integration flow.
→ pccx v002 — Architecture & ISA spec · Gemma 3N E4B on pccx v002 · 한국어 문서
Related repos: pccx (spec) · pccx-lab (profiler / simulator) · llm-bottleneck-lab (related research)
Public alpha — v0.1.0-alpha is published as a prerelease. Core
RTL and ISA are available; verification and KV260 bring-up are in
progress. This is not a bitstream release. Feedback and issues are
welcome.
| Entry point | Link |
|---|---|
| Architecture & ISA spec | https://pccx.pages.dev/en/docs/v002/index.html |
| RTL consumed by KV260 | third_party/pccx-v002/LLM/rtl/ + third_party/pccx-v002/common/rtl/ via hw/vivado/filelist.v002.f; top pccx_npu_top.sv |
| Releases | https://github.com/pccxai/pccx-FPGA-NPU-LLM-kv260/releases |
v0.1.0-alpha notes |
docs/releases/v0.1.0-alpha.md |
| Roadmap (project board) | https://github.com/orgs/pccxai/projects/1 |
| Contributing | https://github.com/pccxai/.github/blob/main/CONTRIBUTING.md |
| How to cite | CITATION.cff |
| Verification check | repo-validate required on main. The v002 Sail typecheck runs in pccxai/pccx-v002. |
| Discussions (board bring-up, RTL Q&A) | https://github.com/pccxai/pccx-FPGA-NPU-LLM-kv260/discussions |
| Good first issues |
good first issue
|
The repository Wiki is intentionally empty — RTL- and bring-up questions belong in Discussions, and the canonical architecture documentation lives on the pccx Sphinx site.
| Layer | Lives in | Authoritative source |
|---|---|---|
| Architecture / ISA / driver spec | pccx/docs/v002/ |
pccx v002 docs |
| Target-model pipeline (Gemma 3N E4B) | pccx/docs/v002/Models/ |
Models section |
| Reusable v002 IP-core RTL | third_party/pccx-v002/LLM/, third_party/pccx-v002/common/ |
pccx-v002 compatibility contract + third_party/PINS.md |
| KV260 Vivado integration | this repo — hw/vivado/ |
Wrapper, Tcl flow, and filelist.v002.f |
| Bare-metal driver (C/C++) | this repo — sw/driver/ |
API spec: Drivers/api |
| Application (planned, v0.2.0) | this repo — sw/gemma3NE4B/ (not yet in tree) |
— |
If you want to read about how the accelerator works, head to the pccx v002 docs — that's the canonical source for every architectural decision in this repo. If you want to inspect the KV260 integration wrapper, the submodule pin, or the board flow, stay here.
Click the diagram for the annotated top-level page on the pccx site.
Three heterogeneous cores around a centralized L2 URAM cache:
| Core | Shape | What it runs |
|---|---|---|
| Systolic Array (GEMM) | 32 × 16 × 2 | Prefill — Q · Kᵀ across the full context, FFN in prefill |
| GEMV Core | 32 × 1 × 4 | Decode — every projection in the autoregressive step |
| SFU (CVO) | 32 × 1 × 4 | Softmax · GELU · RMSNorm · RoPE · sin/cos · reduce · scale · recip |
- Clock domains: AXI 250 MHz ↔ core 400 MHz, crossed by async CDC FIFOs.
- Weight path: HP0/1 = GEMM weights, HP2/3 = GEMV weights, 128-bit/clk each.
- Activation path: host DDR4 → ACP DMA → L2 URAM (1.75 MB, true dual port).
- Direct-connect FIFO: GEMV → SFU, so softmax runs without an L2 round-trip.
Full rationale and numbers: Top-Level → · Design rationale →
Weight-stationary 2D systolic layout. Activations broadcast along columns, partial sums propagate vertically into the result accumulator. Used only during prefill; idle during decode.
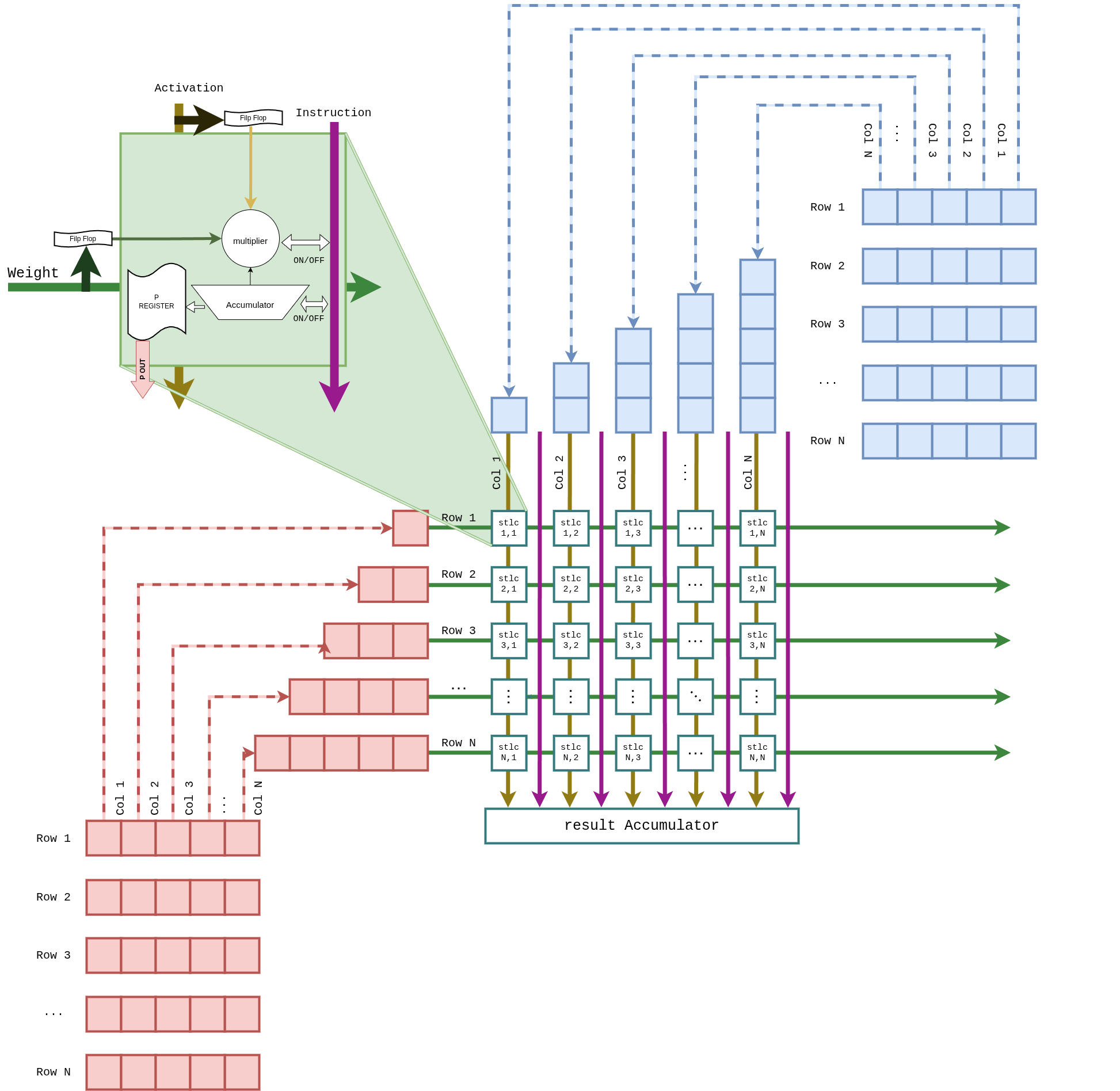
Inside each PE — a DSP48E2 wrapped with input flip-flops on both Activation and Weight ports, and an accumulator with a P-register output:
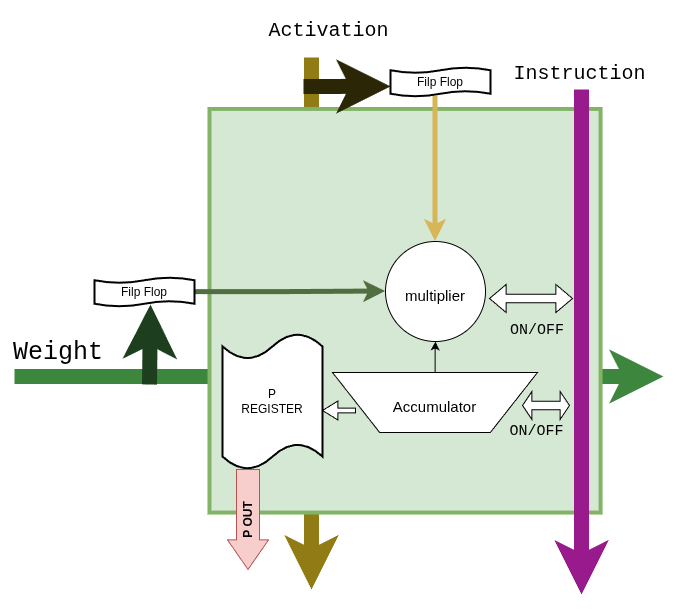
Details: GEMM core → · GEMM dataflow →
Four parallel GEMV lanes, each an 8-wide DSP pipeline fed by an Activation broadcast and a Weight row. Outputs feed a reduction tree that collapses partial products into the final vector entry register. The primary compute path during autoregressive decode.
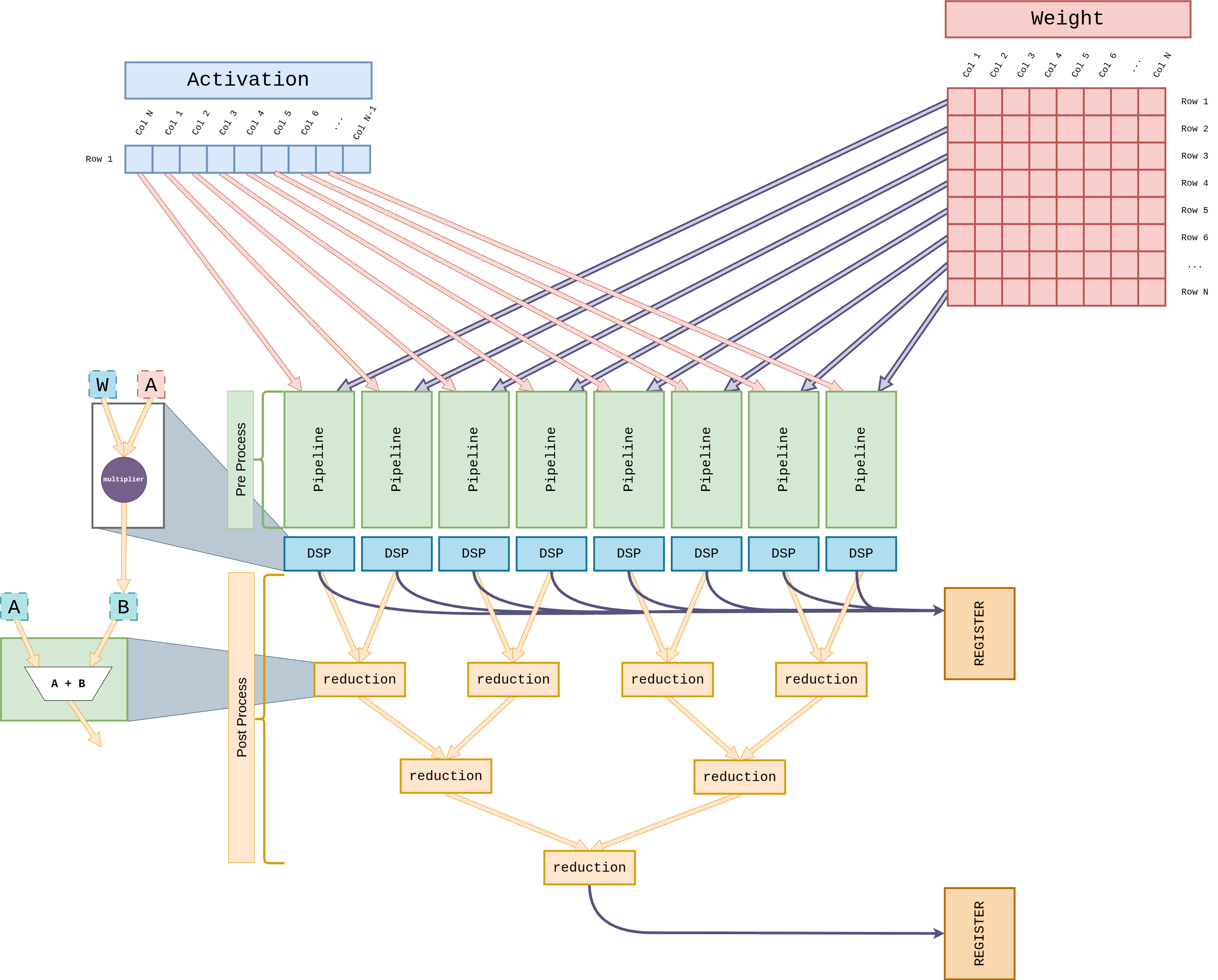
Per-cycle operand shapes — a 1×N activation row multiplied against an N×N weight tile:
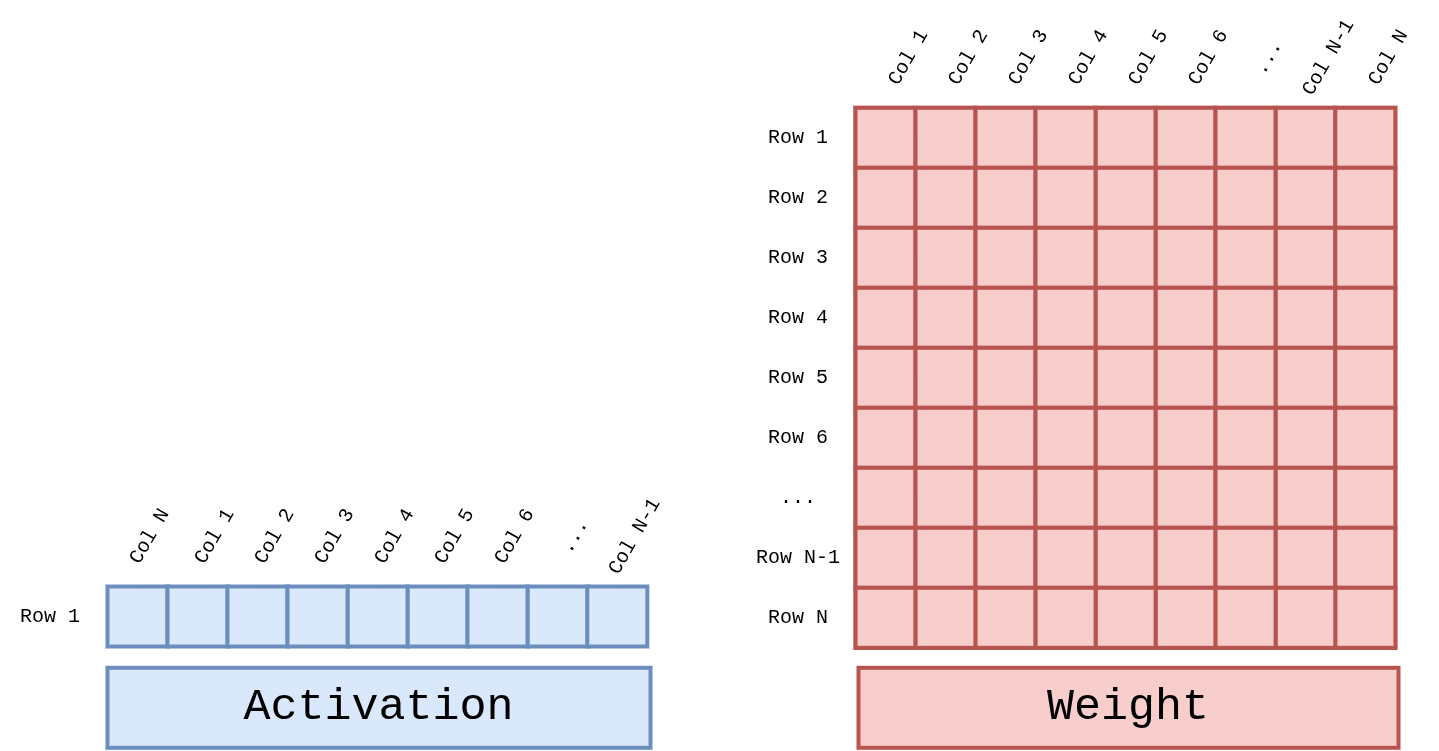
Details: GEMV core → · GEMV dataflow →
The DSP48E2 has a single 27×18 multiplier, not two. pccx v002 bit-packs two INT4 weights into port A alongside a single INT8 activation on port B, so each DSP emits two MACs per cycle into the 48-bit accumulator with a 19-bit guard band between the two channels.
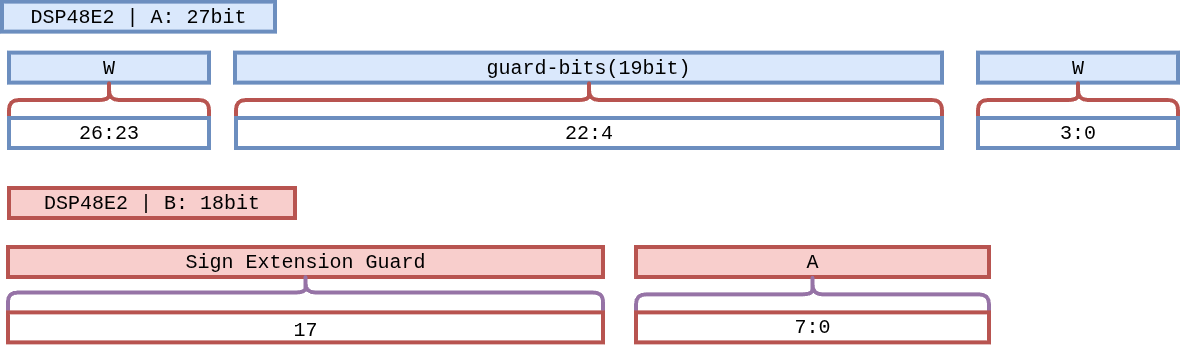
After accumulation, a sign-recovery step restores the upper channel when the lower channel borrowed a carry:

- Maximum accumulations before draining the ACCM: 2^10 ≈ 1024 per channel (guard-band limited).
- For K > 1024 (e.g. Gemma 3N's FFN with K = 16384), the Global Scheduler drains the ACCM every 1024 cycles into a LUT-based adder tree and merges the partial sums.
- Peak: 2048 MAC × 400 MHz ≈ 819 GMAC/s across the two systolic arrays.
Details: DSP48E2 W4A8 bit-packing →
The target model (Google Gemma 3N E4B) has several deviations from a textbook decoder that the scheduler has to honor. The short list:
| Feature | Effect |
|---|---|
| AltUp 4 residual streams | Four copies of xs live in L2; main stream xs[0] stays clean, shadow streams xs[1..3] receive depth-dependent updates. |
| Alternating RoPE θ (5-layer cycle) | θ = 10 000 (local) or 1 000 000 (global), preloaded per-layer via MEMSET. |
| No attention scaling, no softcap | Softmax sequence drops from 4 CVO instructions to 3. |
| LAuReL parallel branch | Two tiny GEMVs (D × 64, 64 × D) + a CVO_SCALE by 1/sqrt(2). |
| PLE shadow-stream injection | Per-Layer Embedding only touches xs[1..3] at the end of each layer; the main stream is untouched. |
| FFN Gaussian Top-K sparsity (L0–9) | Replaces a sort with Mean + 1.645·Std; ~95 % of gate_raw becomes zero and W_down skips masked rows. |
| Cross-layer KV sharing | Only layers 0–19 own their KV cache; layers 20–34 reuse layer 18 (local) or 19 (global). Cache shape is [20, L, 512], not [35, L, 512]. |
End-to-end decode flow, per-cycle overlap strategy, instruction-level mapping, memory layout, and the performance budget all live in the pccx Models section:
- Gemma 3N overview
- Full operator pipeline (embedding → sampling)
- Attention & RoPE constraints
- PLE & LAuReL routing rules
- FFN Gaussian Top-K sparsity
- Execution & scheduling on pccx v002
Five opcodes, 64 bits each: [63:60] opcode + [59:0] body.
| Opcode | Mnemonic | Use |
|---|---|---|
4'h0 |
OP_GEMV |
Vector × Matrix — decode projections |
4'h1 |
OP_GEMM |
Matrix × Matrix — prefill Q·Kᵀ, A·V across full sequence |
4'h2 |
OP_MEMCPY |
Host DDR4 ↔ L2 DMA (ACP) |
4'h3 |
OP_MEMSET |
Write shape / size / scale constants to the Constant Cache |
4'h4 |
OP_CVO |
Element-wise non-linear (exp, sqrt, GELU, sin, cos, reduce_sum, scale, recip) |
Spec: Per-instruction encoding → · Dataflow per opcode →
The pipeline is fully decoupled: the front-end decodes and enqueues into per-engine FIFOs, and each compute engine fires independently once its local dependencies (weight stream, fmap ready) are satisfied. A stall in one engine never halts another.
GEMV flags.findemax=1 ; Q · Kᵀ, track e_max
CVO CVO_EXP flags.sub_emax=1 ; exp(score - e_max)
CVO CVO_REDUCE_SUM ; Σ exp → scalar
CVO CVO_SCALE flags.recip_scale=1 ; divide each exp by the sum
KV bandwidth (not FLOPs) is what pins down L on KV260. At 32 K context
the cumulative cache would hit ~1.31 GB, and DDR4's ~10 GB/s puts
floor-to-floor read time above 130 ms per token. Three mitigations,
enforced at RTL / memory controller / driver level:
- KV quantization — DRAM format is INT8 (default) or INT4. 2–4× bandwidth and capacity savings, aligned with the W4A8 compute path.
- Attention-sink + local-window eviction — the driver retains only the first few tokens and a sliding recent window; middle tokens are evicted on a schedule, combined with Google Turbo-Quant-style requantization.
- Hard cap — the KV ring-buffer ceiling is set at init
(
max_tokens = 8192). Wrap-around overwrites the oldest entries. This bounds both OOM risk and worst-case memory traffic.
Details: KV cache strategy →
This repository remains the KV260 + PCCX v002 LLM application
integration repo. Reusable v002 IP-core ownership is in pccx-v002 and
is consumed here through the pinned third_party/pccx-v002 submodule;
future v003 IP-core ownership will be separate in pccx-v003.
| Track | Owner | Target model | Scope | Status |
|---|---|---|---|---|
| v002 integration | this repo + pccx-v002 |
Gemma 3N E4B | KV260 board flow, bare-metal driver, application wiring, and v002 LLM package consumption | In progress |
| v003 IP-core | pccx-v003 |
Gemma 4 E4B | Separate IP-core line and compatibility contract | Future / TBD |
third_party/pccx-v002supplies the consumed v002 IP-core sources.hw/vivado/filelist.v002.fis the KV260 integration compile entry for the submodule-backed RTL.- v003 RTL belongs to the separate IP-core repository line.
Full phase-by-phase plan, decision points, compute budget, and Year 2 Auto-Porting Pipeline α vision:
→ Roadmap (EN) · 한국어
| Block | Status |
|---|---|
| Custom VLIW ISA | Spec complete |
| VLIW frontend + decoder | RTL complete |
| Global Scheduler | RTL complete |
| Systolic Array (Matrix Core, v001 32×32) | RTL complete |
| GEMV pipeline (Vector Core, 4 lanes) | RTL complete |
| CVO SFU + CORDIC | RTL complete |
| FMap preprocessing (BF16 → fixed-pt) | RTL complete |
| L2 URAM cache + ACP DMA | RTL complete |
| CVO ↔ L2 stream bridge | RTL complete |
| NPU top-level wiring | RTL complete |
| Python golden model | Verified |
| pccx v002 re-parameterization (1 DSP = 2 MAC) | In progress |
| uXC driver (AXI-Lite HAL) | Skeleton |
Gemma 3N E4B application (sw/gemma3NE4B/) |
Planned (v0.2.0) — not yet in tree |
| Simulation / trace-driven verification | xsim smoke suite active |
| Vivado synthesis + timing closure | Synth attempted; no completed report yet. Timing closure pending. |
The reusable RTL previously carried under
hw/rtl/now comes fromthird_party/pccx-v002/LLM/rtl/andthird_party/pccx-v002/common/rtl/. The KV260-specific wrapper remains athw/vivado/npu_core_wrapper.sv.
hw/
vivado/
filelist.v002.f ← forwards to third_party/pccx-v002/LLM/scripts/filelist.f
npu_core_wrapper.sv ← plain-signal wrapper around pccx_npu_top
*.tcl ← KV260 Vivado project, synth, and impl flow
sw/
driver/ ← AXI-Lite MMIO HAL + inference API (skeleton)
gemma3NE4B/ ← Gemma 3N E4B application — planned for v0.2.0, not yet in tree
docs/ ← Redirect stub only — full docs live on pccx
scripts/v002/ ← submodule sim wrapper and local candidate checks
third_party/pccx-v002/ ← pinned v002 IP-core submodule
docs/ in this repo is intentionally a redirect stub. All
architectural and model documentation now lives in the pccx repo /
GitHub Pages site.
The repo runs the v002 xsim harness through
scripts/v002/use_submodule_sources.sh, which forwards to
third_party/pccx-v002/LLM/sim/run_verification.sh with the pinned
submodule RTL root. One command runs the full suite and emits a .pccx
trace per bench for pccx-lab to visualise:
scripts/v002/use_submodule_sources.shFor a shorter local smoke subset:
scripts/v002/use_submodule_sources.sh --quick
scripts/v002/run-local-candidate.sh --quickSee docs/SIMULATION.md for run log paths, PASS verdict rules, and the evidence checklist.
| Testbench | Module(s) under test | Verdict count |
|---|---|---|
tb_shape_const_ram |
shape_const_ram (reset / write / read contract) |
15 |
tb_mem_dispatcher_shape_lookup |
mem_dispatcher + shape_const_ram LOAD pointer routing |
11 |
tb_GEMM_dsp_packer_sign_recovery |
GEMM_dsp_packer + GEMM_sign_recovery (W4A8 dual-MAC) |
1024 |
tb_GEMM_fmap_staggered_delay |
GEMM_fmap_staggered_dispatch (column stagger) |
65 |
tb_GEMM_weight_dispatcher |
GEMM_weight_dispatcher (upper / lower AND-valid) |
128 |
tb_mat_result_normalizer |
mat_result_normalizer (48 b 2sC → BF16 4-stage) |
256 |
tb_FROM_mat_result_packer |
FROM_gemm_result_packer (32 lanes → 4×128 b FSM) |
4 |
tb_barrel_shifter_BF16 |
barrel_shifter_BF16 (BF16 → 27 b fixed-point) |
512 |
tb_ctrl_npu_decoder |
ctrl_npu_decoder (4-bit opcode → one-hot valid) |
6 |
tb_mem_u_operation_queue |
mem_u_operation_queue (queue push / pop smoke) |
32 |
tb_v002_runtime_smoke_program |
v002 ISA .memh -> decoder/scheduler handoff |
7 |
Every bench emits the canonical PASS: line that
pccx-lab's from_xsim_log converter recognises — the
deterministic runner fails nonzero on a missing verdict or explicit
non-PASS verdict.
Reusable testbench registration lives in
third_party/pccx-v002/LLM/sim/run_verification.sh, with testbench
sources under third_party/pccx-v002/LLM/tb/. Changes to that reusable
suite belong in pccx-v002; this repo should only update KV260-specific
runtime inputs and wrappers. See
pccx-lab's verification-workflow doc
for the end-to-end flow diagram and the Tauri IPC surface.
| Surface | Command |
|---|---|
| Full suite runner | run_verification IPC -> scripts/v002/use_submodule_sources.sh |
| Per-tb trace loader | "Open" button per row (calls load_pccx) |
| Synth utilisation | SynthStatusCard (parses hw/build/reports/) |
| Roofline classification | RooflineCard (runs on the loaded trace) |
| Markdown summary | generate_markdown_report IPC |
Apache 2.0 — same as pccx. This protects the architecture from patent risk while keeping the ecosystem open for hardware research.
PCCX™ is a mark used by the PCCX project. Korean trademark
applications are pending for PCCX in Classes 09 and 42. Registration
has not been granted; do not use any registration-mark variant until
the central trademark policy is updated. See
pccx/TRADEMARKS.md.