![]()
PyTorch Sparse Linear Algebra - A differentiable sparse linear equation solver library with multiple backends.
📖 Introduction • 🔧 Installation • 📚 API Reference • 💡 Examples • 📊 Benchmarks
- 🔥 Differentiable: Full gradient support through
torch.autograd - 🚀 Multiple Backends: SciPy, Eigen (CPU), CuPy, cuDSS, PyTorch-native (CUDA)
- 📦 Batched Operations: Support for batched sparse tensors
[..., M, N, ...] - 🎯 Property Detection: Auto-detect symmetry and positive definiteness
- ⚡ High Performance: Auto-selects best solver based on device, dtype, and problem size
- 🌐 Distributed: Domain decomposition with halo exchange (CFD/FEM style)
- 🔧 Easy to Use:
SparseTensorclass with solve, norm, eigs methods - 🧮 Nonlinear Solve: Adjoint-based Newton/Anderson solvers with implicit differentiation
# Basic installation
pip install torch-sla
# GPU users: choose one or both CUDA 12+ backends
pip install torch-sla[cupy] # + CuPy backend
pip install torch-sla[cudss] # + cuDSS backend (fastest direct solver on GPU)
# Full installation with all runtime backends (does not include dev/docs)
pip install torch-sla[all]
# From source (for development)
git clone https://github.com/walkerchi/torch-sla.git
cd torch-sla
pip install -e ".[dev]" # development tools (pytest, black, isort, mypy)
pip install -e ".[docs]" # documentation tools (sphinx, furo)Note: The core install (
pip install torch-sla) pulls intorch,numpy,scipy, andninja— enough to run CPU solvers out of the box.torch-sla[all]additionally bundlespytest,nvmath-python, andcupy-cuda12x, but does not include[dev]or[docs]— install those separately if needed.
After installation, you can inspect which backends are available on your machine:
import torch_sla
torch_sla.show_backends()import torch
from torch_sla import SparseTensor
# Create sparse matrix from dense (for small matrices)
dense = torch.tensor([[4.0, -1.0, 0.0],
[-1.0, 4.0, -1.0],
[ 0.0, -1.0, 4.0]], dtype=torch.float64)
A = SparseTensor.from_dense(dense)
# Solve Ax = b
b = torch.tensor([1.0, 2.0, 3.0], dtype=torch.float64)
x = A.solve(b)
# Specify backend and method
x = A.solve(b, backend='scipy', method='lu')# Move to CUDA
A_cuda = A.cuda()
b_cuda = b.cuda()
# Auto-selects cudss+cholesky (best for CUDA)
x = A_cuda.solve(b_cuda)
# Or explicitly specify
x = A_cuda.solve(b_cuda, backend='cudss', method='cholesky')
# For very large problems (DOF > 2M), use iterative
x = A_cuda.solve(b_cuda, backend='pytorch', method='cg')Based on benchmarks on 2D Poisson equations (tested up to 400M DOF multi-GPU):
| Problem Size | CPU | CUDA | Notes |
|---|---|---|---|
| Small (< 100K DOF) | scipy+lu |
cudss+cholesky |
Direct solvers, machine precision |
| Medium (100K - 2M DOF) | scipy+lu |
cudss+cholesky |
cuDSS is fastest on GPU |
| Large (2M - 169M DOF) | N/A | pytorch+cg |
Iterative only, ~1e-6 precision |
| Very Large (> 169M DOF) | N/A | DSparseTensor multi-GPU |
Multi-GPU domain decomposition |
- PyTorch CG+Jacobi scales to 169M+ DOF on single GPU with near-linear O(n^1.1) complexity
- Multi-GPU scales to 400M+ DOF with DSparseTensor domain decomposition (3x H200)
- Direct solvers limited to ~2M DOF due to memory (O(n^1.5) fill-in)
- Use float64 for best convergence with iterative solvers
- Trade-off: Direct = machine precision (~1e-14), Iterative = ~1e-6 but 100x faster
| Backend | Device | Description | Recommended For |
|---|---|---|---|
scipy |
CPU | SciPy (LU/UMFPACK) | CPU default - fast + machine precision |
eigen |
CPU | Eigen C++ (CG, BiCGStab) | Alternative CPU iterative |
cupy |
CUDA | CuPy (LU, CG, GMRES) | GPU direct + iterative via cupyx.scipy |
cudss |
CUDA | NVIDIA cuDSS (LU, Cholesky, LDLT) | CUDA default - fastest direct |
pytorch |
CUDA | PyTorch-native (CG, BiCGStab) | Very large problems (> 2M DOF) |
| Method | Backends | Best For | Precision |
|---|---|---|---|
lu |
scipy, cupy, cudss | General matrices (direct) | Machine precision |
cholesky |
cudss | SPD matrices (fastest) | Machine precision |
ldlt |
cudss | Symmetric matrices | Machine precision |
umfpack |
scipy | General matrices (requires scikit-umfpack) | Machine precision |
cg |
scipy, eigen, cupy, pytorch | SPD matrices (iterative) | ~1e-6 to 1e-7 |
bicgstab |
scipy, eigen, pytorch | General (iterative) | ~1e-6 to 1e-7 |
gmres |
scipy, cupy | General (iterative) | ~1e-6 to 1e-7 |
Two batched solving modes are supported:
Batched matrices — same sparsity structure, different values per batch:
batch_size = 4
val_batch = val.unsqueeze(0).expand(batch_size, -1).clone()
# Create batched SparseTensor [B, M, N]
A = SparseTensor(val_batch, row, col, (batch_size, 3, 3))
b = torch.randn(batch_size, 3, dtype=torch.float64)
x = A.solve(b) # Shape: [batch_size, 3]Multiple right-hand sides — single matrix, multiple RHS columns (factorized once for direct solvers):
A = SparseTensor(val, row, col, (3, 3))
b = torch.randn(3, 5, dtype=torch.float64) # 5 right-hand sides
x = A.solve(b) # Shape: [3, 5]For large-scale problems across multiple GPUs, use domain decomposition.
DSparseTensor mirrors torch.distributed.tensor.DTensor: each rank
holds its own SparseTensor chunk plus a Partition map (owned rows +
halo), and every operation stays in Shard(0) space.
import torch.distributed as dist
from torch.distributed.device_mesh import init_device_mesh
from torch_sla import SparseTensor, DSparseTensor, solve, SolverConfig
dist.init_process_group(backend="nccl") # or "gloo" for CPU
mesh = init_device_mesh("cuda", (dist.get_world_size(),))
A = SparseTensor(val, row, col, shape)
D = DSparseTensor.partition(A, mesh, partition_method="metis")
b_dt = D.scatter(b_global)
# Distributed Krylov solve via the unified API. SolverConfig flows in;
# x_dt is a DTensor[Shard(0)] composable with the rest of FSDP/TP.
with SolverConfig(method="cg", atol=1e-10, rtol=1e-10, maxiter=2000):
x_dt = solve(D, b_dt)
# Residual / global gather via public ops only.
r_dt = b_dt - D @ x_dt
x_full = x_dt.full_tensor()# Run with 4 GPUs
torchrun --standalone --nproc_per_node=4 your_script.pyAll operations support automatic differentiation:
val = val.requires_grad_(True)
b = b.requires_grad_(True)
x = A.solve(b)
loss = x.sum()
loss.backward()
print(val.grad) # Gradient w.r.t. matrix values
print(b.grad) # Gradient w.r.t. RHS| Operation | CPU | CUDA | Notes |
|---|---|---|---|
solve() |
✓ | ✓ | Adjoint method, O(1) graph nodes |
det() |
✓ | ✓ | Adjoint method, ∂det/∂A = det(A)·(A⁻¹)ᵀ |
eigsh() / eigs() |
✓ | ✓ | Adjoint method, O(1) graph nodes |
svd() |
✓ | ✓ | Power iteration, differentiable |
nonlinear_solve() |
✓ | ✓ | Adjoint, params only |
@ (A @ x, SpMV) |
✓ | ✓ | Standard autograd |
@ (A @ B, SpSpM) |
✓ | ✓ | Sparse gradients |
+, -, * |
✓ | ✓ | Element-wise ops |
T() (transpose) |
✓ | ✓ | View-like, gradients flow through |
norm(), sum(), mean() |
✓ | ✓ | Standard autograd |
to_dense() |
✓ | ✓ | Standard autograd |
| Operation | CPU (Gloo) | CUDA (NCCL) | Notes |
|---|---|---|---|
D @ x_dt |
✓ | ✓ | Halo exchange + local SpMV → DTensor[Shard(0)] |
solve(D, b_dt) |
✓ | ✓ | CG / BiCGStab / GMRES / FGMRES / MINRES |
D.eigsh(k=) |
✓ | ✓ | Distributed LOBPCG (sharded matvec, global RR) |
D.sum / .mean / .max / .min / .prod |
✓ | ✓ | Cross-rank all_reduce over stored values |
D.norm('fro' / 1 / inf) |
✓ | ✓ | Single all_reduce; 2 falls back to gather |
D.is_symmetric / .is_hermitian / .is_positive_definite |
✓ | ✓ | Cached full_tensor + single-process check |
D.detect_matrix_type() |
✓ | ✓ | Same; for solve(..., matrix_type='auto') |
D.T() / .H() |
✓ | ✓ | Allgather → transpose → repartition on same mesh |
D + s, D * s, D.abs(), etc. |
✓ | ✓ | Local elementwise, same _spec |
D.save(dir) / DSparseTensor.load(dir, mesh) |
✓ | ✓ | Per-rank partition_<rank>.safetensors + metadata.json |
D.full_tensor() |
✓ | ✓ | All-gather to a global SparseTensor |
D.det() / .lu() / .svd() / .condition_number() |
✓ | ✓ | Falls back to full_tensor() + single-proc; emits ResourceWarning |
| Operation | CPU (Gloo) | CUDA (NCCL) | Notes |
|---|---|---|---|
D @ x |
✓ | ✓ | Embarrassingly parallel — each rank multiplies its own batch slice |
D.eigsh(k=) |
✓ | ✓ | Per-rank batched LOBPCG on the local slice (zero comm) |
D.solve_batch_shard(b) |
✓ | ✓ | Per-rank batched solve via SparseTensor.solve_batch (zero comm) |
D.sum / .mean / .max / .min / .norm('fro') |
✓ | ✓ | Single all_reduce across batch ranks |
D.full_tensor() |
✓ | ✓ | Allgather padded values along the sharded batch axis |
Communication per Krylov iteration (VertexShard): halo exchange + 1–2
all_reduce (method-dependent). All vectors stay sharded; no global
gather. BatchShard has zero inter-rank comm in the inner loop.
Save and load SparseTensor instances using safetensors:
from torch_sla import SparseTensor, save_sparse, load_sparse
A = SparseTensor(val, row, col, shape)
A.save("matrix.safetensors")
A = SparseTensor.load("matrix.safetensors", device="cuda")
# Matrix Market interop
from torch_sla import save_mtx, load_mtx
save_mtx(A, "matrix.mtx")
A = load_mtx("matrix.mtx")Distributed (DSparseTensor) persistence: gather to a global
SparseTensor via D.full_tensor() and save that.
Solve nonlinear equations F(u, A, θ) = 0 with automatic differentiation using the adjoint method:
from torch_sla import SparseTensor
# Create sparse matrix (e.g., FEM stiffness matrix)
A = SparseTensor(val, row, col, (n, n))
# Define nonlinear residual: A @ u + u² = f
def residual(u, A, f):
return A @ u + u**2 - f
# Parameters with gradients
f = torch.randn(n, requires_grad=True)
u0 = torch.zeros(n)
# Solve with Newton-Raphson
u = A.nonlinear_solve(residual, u0, f, method='newton')
# Gradients flow via adjoint method
loss = u.sum()
loss.backward()
print(f.grad) # ∂L/∂f via implicit differentiationMethods:
newton: Newton-Raphson with line search (default, fast convergence)picard: Fixed-point iteration (simple, slow)anderson: Anderson acceleration (memory efficient)
Key Features:
- Memory-efficient adjoint method (no Jacobian storage)
- Jacobian-free Newton-Krylov via autograd
- Multiple parameters with mixed requires_grad
- Seamless integration with
SparseTensorclass
# Create sparse matrix from dense (for small matrices)
dense = torch.tensor([[4.0, -1.0, 0.0],
[-1.0, 4.0, -1.0],
[ 0.0, -1.0, 4.0]], dtype=torch.float64)
A = SparseTensor.from_dense(dense)
# Norms
norm = A.norm('fro') # Frobenius norm
# Determinant (with gradient support)
det = A.det() # ∂det/∂A = det(A)·(A⁻¹)ᵀ
# Note: CPU is faster for sparse matrices (CUDA uses dense conversion)
# For CUDA tensors: A_cuda.cpu().det() is ~3x faster than A_cuda.det()
# Eigenvalues
eigenvalues, eigenvectors = A.eigsh(k=6)
# SVD
U, S, Vt = A.svd(k=10)
# Matrix-vector product
y = A @ x
# LU factorization for repeated solves
lu = A.lu()
x = lu.solve(b)2D Poisson equation (5-point stencil), NVIDIA H200 (140GB), float64:
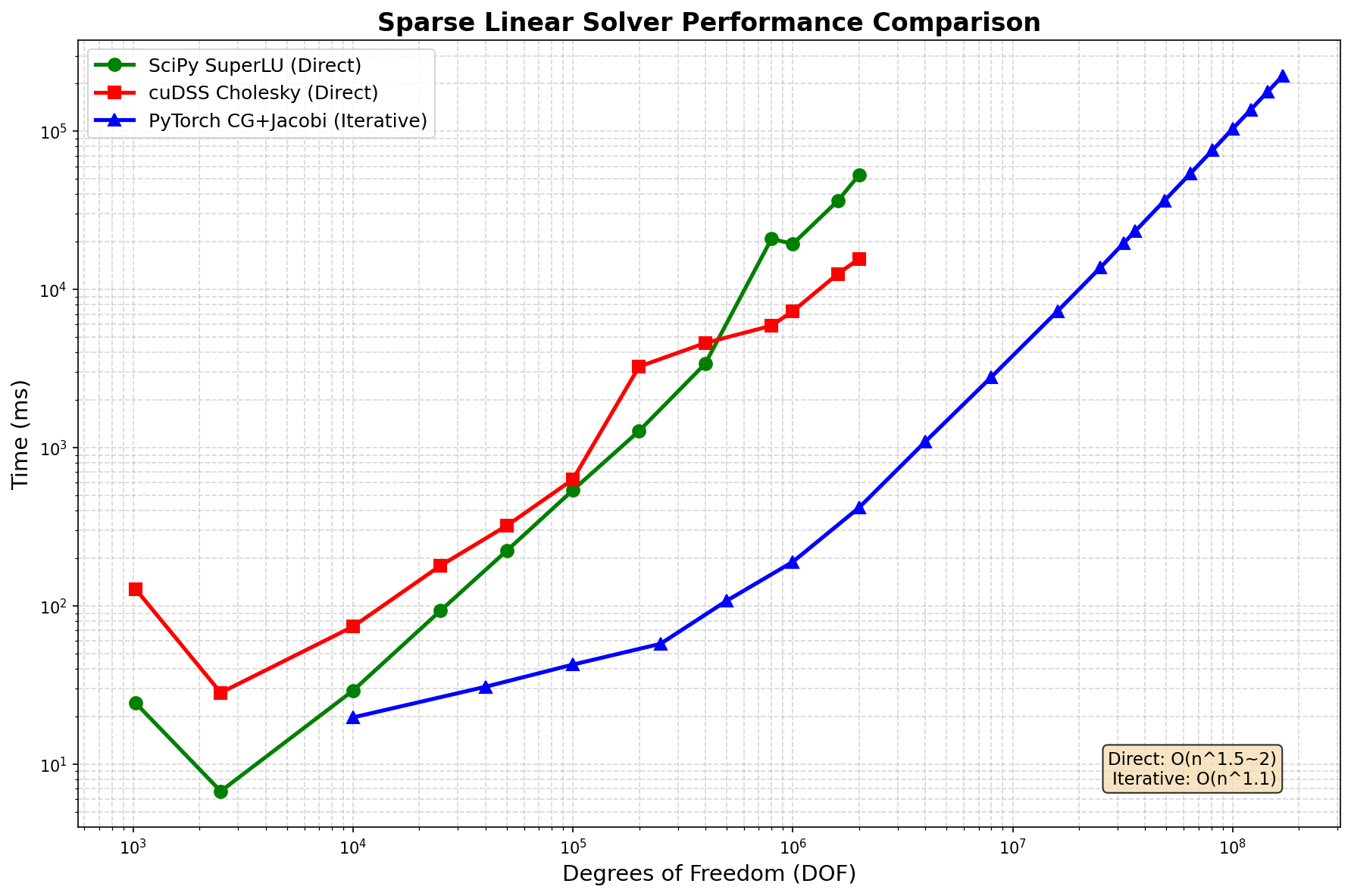
| DOF | SciPy LU | cuDSS Cholesky | PyTorch CG+Jacobi |
|---|---|---|---|
| 10K | 24ms | 128ms | 20ms |
| 100K | 29ms | 630ms | 43ms |
| 1M | 19.4s | 7.3s | 190ms |
| 2M | 52.9s | 15.6s | 418ms |
| 16M | - | - | 7.3s |
| 81M | - | - | 75.9s |
| 169M | - | - | 224s |
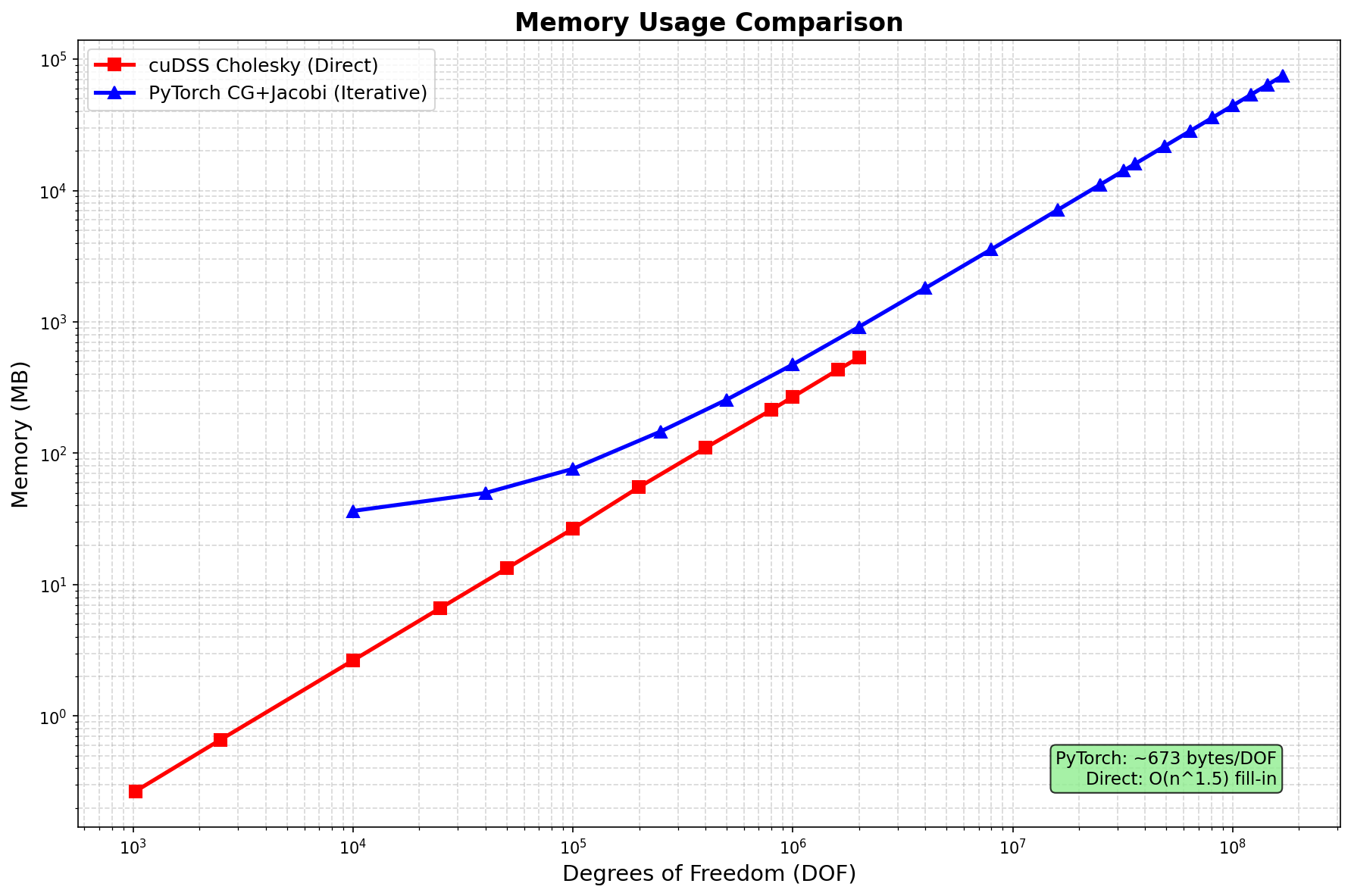
| Method | Memory Scaling | Notes |
|---|---|---|
| SciPy LU | O(n^1.5) fill-in | CPU only, limited to ~2M DOF |
| cuDSS Cholesky | O(n^1.5) fill-in | GPU, limited to ~2M DOF |
| PyTorch CG+Jacobi | O(n) ~443 bytes/DOF | Scales to 169M+ DOF |
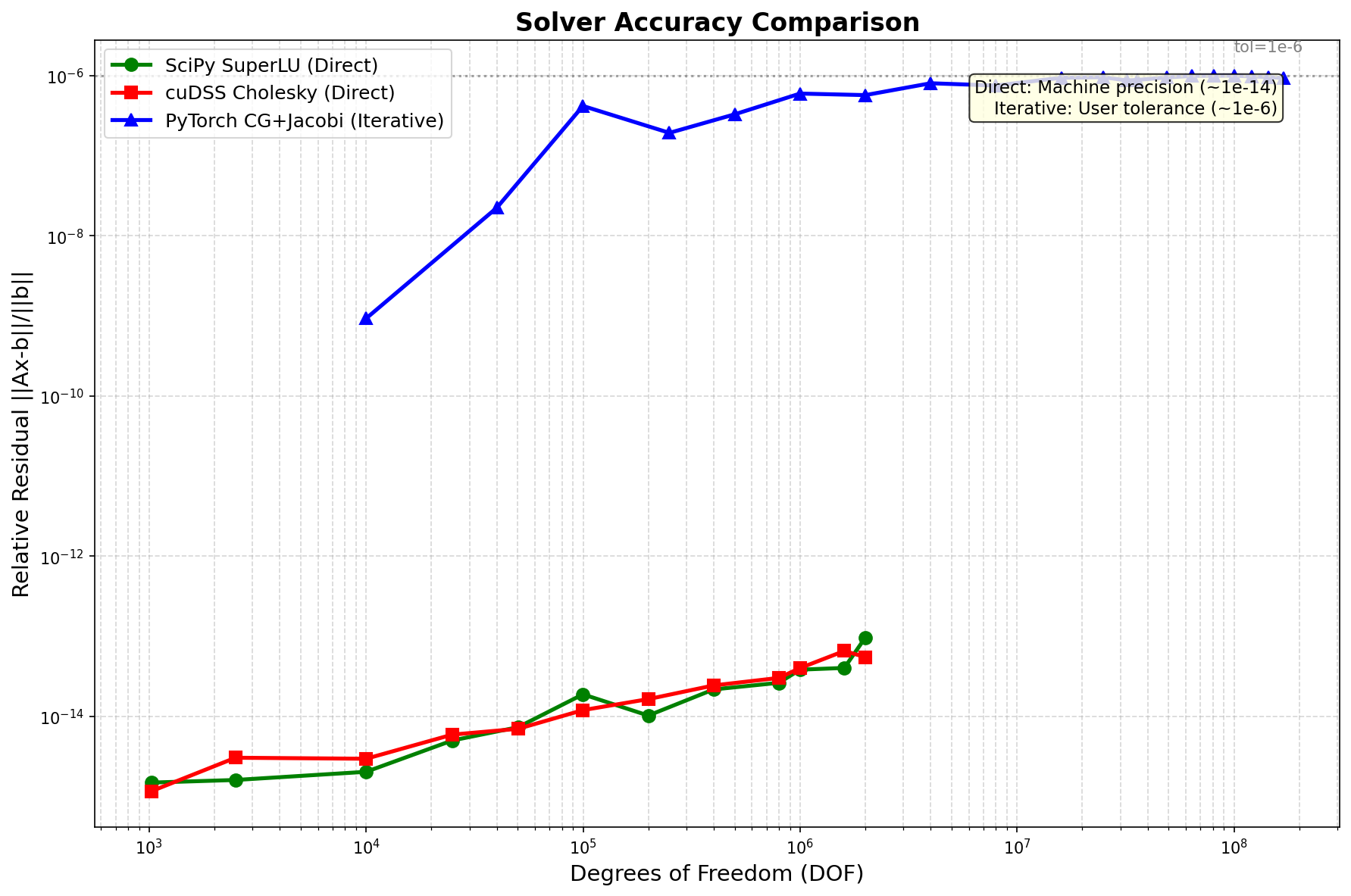
| Method | Precision | Notes |
|---|---|---|
| Direct solvers | ~1e-14 | Machine precision |
| Iterative (tol=1e-6) | ~1e-6 | User-configurable tolerance |
- Iterative solver scales to 169M DOF with O(n^1.1) time complexity
- Direct solvers limited to ~2M DOF due to O(n^1.5~2) memory fill-in
- PyTorch CG+Jacobi is 100x faster than direct solvers at 2M DOF
- Memory efficient: 443 bytes/DOF (vs theoretical minimum 144 bytes/DOF)
- Trade-off: Direct solvers achieve machine precision, iterative achieves ~1e-6
3-4x NVIDIA H200 GPUs with NCCL backend:
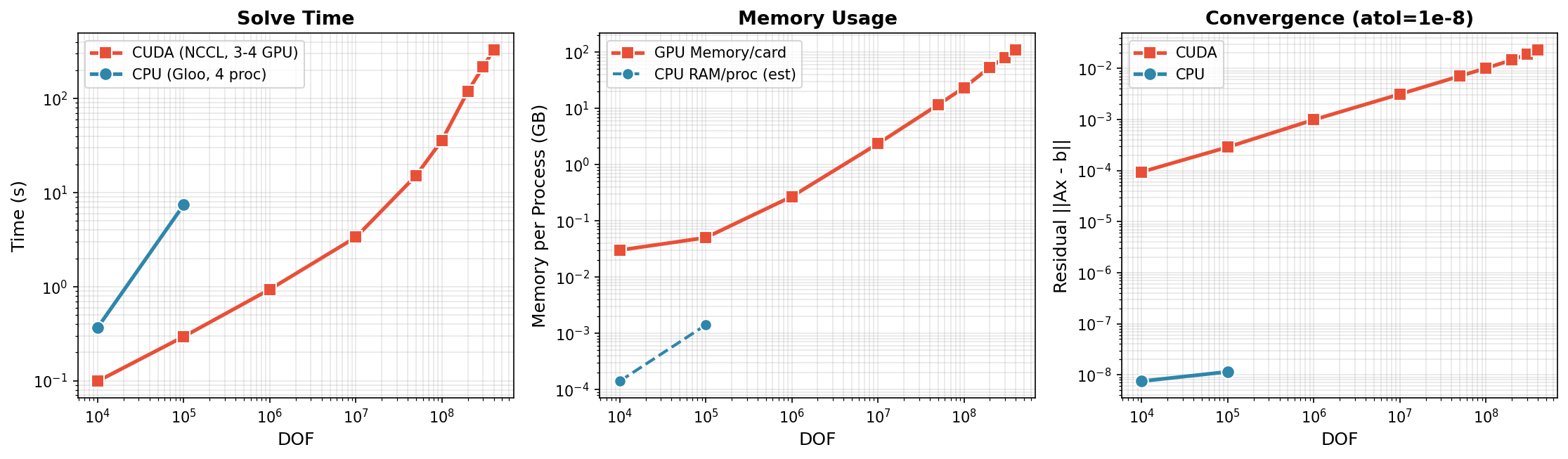
CUDA (3-4 GPU, NCCL) - Scales to 400M DOF:
| DOF | Time | Memory/GPU | Notes |
|---|---|---|---|
| 10K | 0.1s | 0.03 GB | 4 GPU |
| 100K | 0.3s | 0.05 GB | 4 GPU |
| 1M | 0.9s | 0.27 GB | 4 GPU |
| 10M | 3.4s | 2.35 GB | 4 GPU |
| 50M | 15.2s | 11.6 GB | 4 GPU |
| 100M | 36.1s | 23.3 GB | 4 GPU |
| 200M | 119.8s | 53.7 GB | 3 GPU |
| 300M | 217.4s | 80.5 GB | 3 GPU |
| 400M | 330.9s | 110.3 GB | 3 GPU |
Key Findings:
- Scales to 400M DOF on 3x H200 GPUs (110 GB/GPU)
- Near-linear scaling: 10M→400M is 40x DOF, ~100x time
- Memory efficient: ~275 bytes/DOF per GPU
- 500M DOF requires >140GB/GPU, exceeds H200 capacity
# Run distributed solve with 4 GPUs
torchrun --standalone --nproc_per_node=4 examples/distributed/distributed_solve.pySparseTensor- Wrapper with batched solve, norm, eigs, svd methodsSparseTensorList- List of SparseTensors with batched operations and isolated graph priorsDSparseTensor- Distributed sparse tensor with halo exchangeDSparseTensorList- Distributed list for batched graph operations across GPUsLUFactorization- LU factorization for repeated solves

| Single Matrix | List (isolated graph priors) | |
|---|---|---|
| Local | SparseTensor |
SparseTensorList |
| Distributed | DSparseTensor |
DSparseTensorList |
Conversions:
- Horizontal:
to_block_diagonal()/to_connected_components()/to_list() - Vertical:
partition()/gather()
spsolve(val, row, col, shape, b, backend='auto', method='auto')- Solve Ax=bspsolve_coo(A_sparse, b, **kwargs)- Solve using PyTorch sparse tensornonlinear_solve(residual_fn, u0, *params, method='newton')- Solve F(u,θ)=0 with adjoint gradients
get_available_backends()- List available backendsget_backend_methods(backend)- List methods for a backendselect_backend(device, n, dtype)- Auto-select backendis_scipy_available(),is_cudss_available(), etc.
- Use float64 for iterative solvers (better convergence)
- Use cholesky for SPD matrices (2x faster than LU)
- Use scipy+lu for CPU (all sizes)
- Use cudss+cholesky for CUDA (up to ~2M DOF)
- Use pytorch+cg for very large problems (> 2M DOF)
- Use cupy for GPU iterative solvers (CG, GMRES) or as a direct solver fallback
- Use LU factorization for repeated solves with same matrix
- Determinant computation:
- Use CPU for sparse matrices - CUDA requires dense conversion (much slower)
- For CUDA tensors, use
.cpu().det().cuda()for better performance - Use float64 for numerical stability
- Avoid for very large matrices (det values can overflow)
- For distributed matrices, be aware of data gather overhead
- Singular matrices may cause LU decomposition to fail
- Python >= 3.8
- PyTorch >= 1.10.0
- SciPy (recommended for CPU)
- CUDA Toolkit (for GPU backends)
- nvmath-python (optional, for cuDSS backend)
- cupy-cuda12x (optional, for CuPy backend)
# ❌ Slow for sparse matrices
det = A_cuda.det() # 2.5 ms
# ✅ Fast - use CPU even for CUDA tensors
det = A_cuda.cpu().det() # 1.3 ms (1.9x faster!)Why? cuDSS doesn't expose sparse determinant, requiring O(n²) dense conversion. CPU sparse LU is O(nnz^1.5), much faster for sparse matrices.
- Small matrices (< 1000): Use CPU with SciPy backend
- Large matrices (> 1000): Use CUDA with cuDSS backend
- Iterative methods: Use
method='cg'ormethod='bicgstab'for large systems
See benchmarks/README.md for detailed performance analysis.
We welcome contributions! Please see CONTRIBUTING.md for:
- Development workflow
- Code conventions
- Testing guidelines
- Benchmark standards
- Release process (push a
vX.Y.Ztag → auto-publish to PyPI)
Quick conventions:
- Benchmarks:
benchmarks/benchmark_<feature>.py→results/benchmark_<feature>/ - Examples:
examples/<feature>.py - Tests:
tests/test_<module>.py
See TODO.md for the development roadmap.
Apache License 2.0 - Copyright 2024-2026 Mingyuan Chi and Shizheng Wen. See LICENSE.
If you find this library useful, please cite our paper:
@article{chi2026torchsla,
title={torch-sla: Differentiable Sparse Linear Algebra with Adjoint Solvers and Sparse Tensor Parallelism for PyTorch},
author={Chi, Mingyuan and Wen, Shizheng},
journal={arXiv preprint arXiv:2601.13994},
year={2026},
url={https://arxiv.org/abs/2601.13994}
}