Extract public G2 reviews and product data at scale — with ranked top‑10 competitors per product and an LLM‑ready markdown field for direct RAG ingestion. Runs on Apify.
This repo is the developer entry point for the G2 Reviews Scraper actor: the output shape, copy‑paste API snippets, a full field dictionary, and a short how‑to. The actor itself runs on Apify — no login, proxy, or anti‑bot setup required.
Two modes, one actor:
- Reviews mode — give it G2 product URLs (or bare slugs like
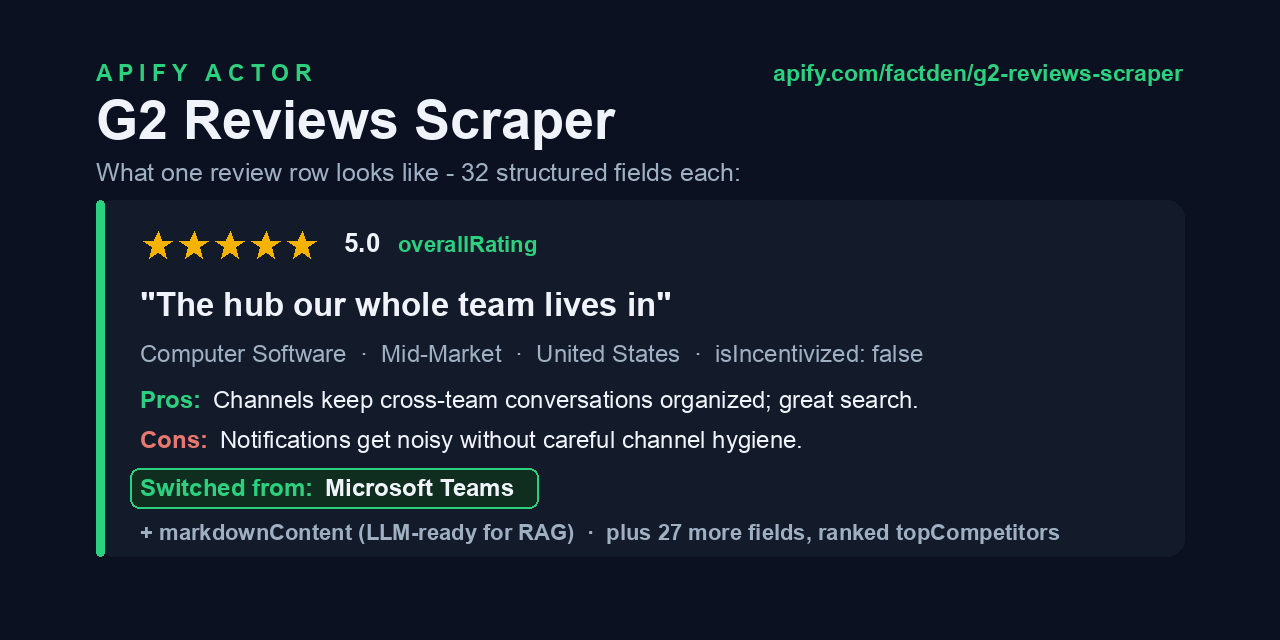
slack) and get every public review as a clean, structured row: 32 fields including 6 sub‑ratings, structuredpros/cons/problemsSolved, switching history with named competitors, reviewer industry / role / company size / country, and an LLM‑readymarkdownContentfield. - Products mode — give it a keyword (e.g.
CRM,communication,project management) and get the top matching products with metadata — competitor discovery before you pull reviews.
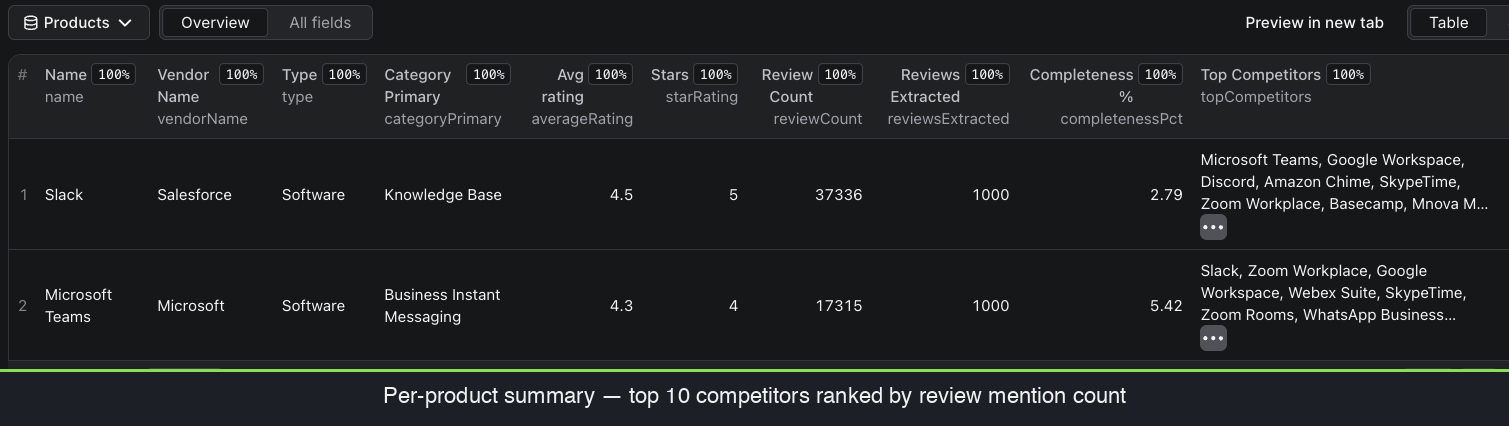
🏆 Ranked top‑10 competitors per product — mined from each reviewer's switching‑from data and resolved to real product names (not opaque IDs). Battlecard‑ready, no aggregation code.
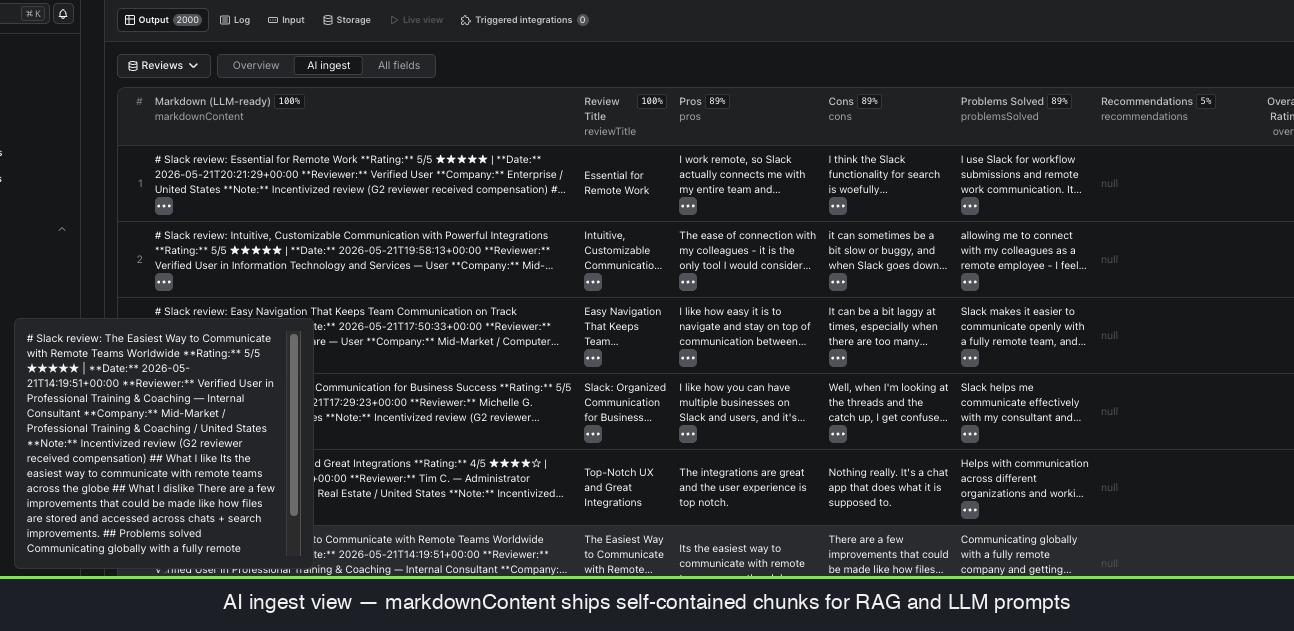
🤖 LLM‑ready markdownContent per review — a self‑contained markdown block, ready for direct vector‑DB / RAG ingestion with zero formatting work.
 |
 |
| Ranked top‑10 competitors per product | LLM‑ready markdownContent field |
from apify_client import ApifyClient
client = ApifyClient("<YOUR_APIFY_TOKEN>")
run = client.actor("factden/g2-reviews-scraper").call(run_input={
"mode": "reviews",
"startUrls": ["https://www.g2.com/products/slack/reviews", "notion"],
"maxReviewsPerProduct": 100,
})
for row in client.dataset(run["defaultDatasetId"]).iterate_items():
print(row["reviewTitle"], row["overallRating"])Real sample output lives in examples/:
examples/reviews-sample-100.csv— 100 real review rows (Slack, Microsoft Teams, Zoom, Google Workspace, Trello) — browse it right in GitHub's table viewexamples/reviews-output.sample.json— 2 review rows showing the full field shape (incl.markdownContent)examples/products-output.sample.json— product rows with rankedtopCompetitorsexamples/input.json— Reviews‑mode input ·examples/input-products.json— Products‑mode input
📊 Full 500-review sample dataset (5 products, download-ready CSV / JSON / JSONL): HuggingFace · Kaggle.
Every field is documented in FIELDS.md. From Apify you can download results as JSON, CSV, Excel, or HTML.
- Competitive battlecards — who switched away from a rival, and why (
previousCompetitors,whySwitched). - Voice‑of‑customer / product research — structured
pros,cons,problemsSolvedacross hundreds of reviews. - AI / RAG pipelines — drop
markdownContentstraight into a vector DB. - Market mapping — Products mode for category discovery and competitor sets.
Pay‑per‑event on Apify: $0.01 per run + $0.004 per row. New Apify accounts get $5 in free credit (~1,250 rows). See the actor page for current pricing.
Is scraping G2 reviews legal? The actor collects only publicly available review data. As with any scraping, review G2's Terms of Service and your local regulations, and use the data responsibly.
Do I need a G2 account or proxies? No. Everything runs inside the actor on Apify's infrastructure.
Found a bug or want a field added? Open an issue here, or use the Issues tab on the Apify actor page.
The sample data in this repo is real public G2 review data, collected with the actor and provided for documentation/evaluation. Run the actor on Apify to pull data for any product, at any scale.