
확장성과 효율성을 위해 설계된 선언적 딥러닝 프레임워크


Ludwig는 LLM 및 기타 심층 신경망과 같은 맞춤형 AI 모델을 구축하기 위한 로우코드 프레임워크입니다.
주요 기능:
- 🛠 손쉬운 맞춤형 모델 구축: 선언적 YAML 설정 파일만으로 최신 LLM을 데이터에 맞춰 학습시킬 수 있습니다. 멀티태스크 및 멀티모달 학습을 지원합니다. 포괄적인 설정 검증으로 잘못된 매개변수 조합을 감지하고 런타임 오류를 방지합니다.
- ⚡ 확장성과 효율성 최적화: 자동 배치 크기 선택, 분산 학습(DDP, DeepSpeed), 매개변수 효율적 미세 조정(PEFT), 4비트 양자화(QLoRA), 페이지 및 8비트 옵티마이저, 메모리 초과 데이터셋 지원.
- 📐 전문가 수준의 제어: 활성화 함수까지 모델을 완전히 제어할 수 있습니다. 하이퍼파라미터 최적화, 설명 가능성, 풍부한 메트릭 시각화를 지원합니다.
- 🧱 모듈식 및 확장 가능: 설정에서 몇 가지 매개변수만 변경하여 다양한 모델 아키텍처, 태스크, 피처, 모달리티를 실험할 수 있습니다. 딥러닝을 위한 빌딩 블록이라고 생각하세요.
- 🚢 프로덕션을 위한 설계: 사전 빌드된 Docker 컨테이너, Kubernetes에서 Ray 실행 네이티브 지원, Torchscript 및 Triton으로 모델 내보내기, 한 번의 명령으로 HuggingFace에 업로드.
Ludwig는 Linux Foundation AI & Data에서 호스팅합니다.
기술 스택: Python 3.12 | PyTorch 2.6 | Pydantic 2 | Transformers 5 | Ray 2.54
PyPI에서 설치합니다. Ludwig는 Python 3.12 이상을 요구합니다.
pip install ludwig모든 선택적 의존성을 포함하여 설치:
pip install ludwig[full]더 자세한 설치 방법은 기여 가이드를 참조하세요.
Ludwig의 기능을 빠르게 살펴보고 싶으시다면 이 Colab 노트북을 확인하세요 🚀
LLM 미세 조정을 원하시나요? 다음 노트북을 확인하세요:
- Fine-Tune Llama-2-7b:
- Fine-Tune Llama-2-13b:
- Fine-Tune Mistral-7b:
전체 튜토리얼은 공식 시작 가이드를 확인하시거나, 엔드투엔드 예제를 살펴보세요.
사전 학습된 LLM을 챗봇처럼 지시를 따르도록 미세 조정("인스트럭션 튜닝")해 봅시다.
- HuggingFace API 토큰
- 선택한 베이스 모델에 대한 접근 승인 (예: Llama-3.1-8B)
- 최소 12 GiB VRAM의 GPU (테스트에서는 Nvidia T4를 사용했습니다)
Stanford Alpaca 데이터셋을 사용합니다. 다음과 같은 테이블 형식의 파일로 구성됩니다:
| instruction | input | output |
|---|---|---|
| Give three tips for staying healthy. | 1.Eat a balanced diet and make sure to include... | |
| Arrange the items given below in the order to ... | cake, me, eating | I eating cake. |
| Write an introductory paragraph about a famous... | Michelle Obama | Michelle Obama is an inspirational woman who r... |
| ... | ... | ... |
model.yaml이라는 YAML 설정 파일을 다음 내용으로 생성하세요:
model_type: llm
base_model: meta-llama/Llama-3.1-8B
quantization:
bits: 4
adapter:
type: lora
prompt:
template: |
Below is an instruction that describes a task, paired with an input that may provide further context.
Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
input_features:
- name: prompt
type: text
output_features:
- name: output
type: text
trainer:
type: finetune
learning_rate: 0.0001
batch_size: 1
gradient_accumulation_steps: 16
epochs: 3
learning_rate_scheduler:
decay: cosine
warmup_fraction: 0.01
preprocessing:
sample_ratio: 0.1
backend:
type: local이제 모델을 학습시켜 봅시다:
export HUGGING_FACE_HUB_TOKEN = "<api_token>"
ludwig train --config model.yaml --dataset "ludwig://alpaca"Rotten Tomatoes 영화 평론가의 리뷰가 긍정적인지 부정적인지 예측하는 신경망을 만들어 봅시다.
데이터셋은 다음과 같은 CSV 파일입니다:
| movie_title | content_rating | genres | runtime | top_critic | review_content | recommended |
|---|---|---|---|---|---|---|
| Deliver Us from Evil | R | Action & Adventure, Horror | 117.0 | TRUE | Director Scott Derrickson and his co-writer, Paul Harris Boardman, deliver a routine procedural with unremarkable frights. | 0 |
| Barbara | PG-13 | Art House & International, Drama | 105.0 | FALSE | Somehow, in this stirring narrative, Barbara manages to keep hold of her principles, and her humanity and courage, and battles to save a dissident teenage girl whose life the Communists are trying to destroy. | 1 |
| Horrible Bosses | R | Comedy | 98.0 | FALSE | These bosses cannot justify either murder or lasting comic memories, fatally compromising a farce that could have been great but ends up merely mediocre. | 0 |
| ... | ... | ... | ... | ... | ... | ... |
여기에서 데이터셋 샘플을 다운로드하세요.
wget https://ludwig.ai/latest/data/rotten_tomatoes.csv다음으로 model.yaml이라는 YAML 설정 파일을 생성하세요:
input_features:
- name: genres
type: set
preprocessing:
tokenizer: comma
- name: content_rating
type: category
- name: top_critic
type: binary
- name: runtime
type: number
- name: review_content
type: text
encoder:
type: embed
output_features:
- name: recommended
type: binary이게 전부입니다! 이제 모델을 학습시켜 봅시다:
ludwig train --config model.yaml --dataset rotten_tomatoes.csv즐거운 모델링 되세요
Ludwig를 여러분의 데이터에 적용해 보세요. 질문이 있으시면 Discord에서 문의해 주세요.
-
최소한의 머신러닝 보일러플레이트
Ludwig는 머신러닝의 엔지니어링 복잡성을 기본으로 처리하여, 연구자들이 가장 높은 수준의 추상화에서 모델 구축에 집중할 수 있게 합니다.
torch.nn.Module모델에 대한 데이터 전처리, 하이퍼파라미터 최적화, 디바이스 관리, 분산 학습이 완전히 무료로 제공됩니다. -
손쉬운 벤치마크 구축
최신 기준 모델을 만들고 새 모델과 비교하는 것이 간단한 설정 변경만으로 가능합니다.
-
새로운 아키텍처를 여러 문제와 데이터셋에 쉽게 적용
Ludwig가 지원하는 광범위한 태스크 및 데이터셋 세트에 새 모델을 적용하세요. Ludwig에는 간단한 설정만으로 여러 데이터셋에서 여러 모델 실험을 실행할 수 있는 전체 벤치마킹 도구가 모든 사용자에게 제공됩니다.
-
데이터 전처리, 모델링, 메트릭의 높은 설정 가능성
모델 아키텍처, 학습 루프, 하이퍼파라미터 검색, 백엔드 인프라의 모든 측면을 선언적 설정에서 추가 필드로 수정하여 파이프라인을 요구 사항에 맞게 커스터마이즈할 수 있습니다. 설정 가능한 항목에 대한 자세한 내용은 Ludwig 설정 문서를 확인하세요.
-
멀티모달, 멀티태스크 학습 기본 지원
코드 작성 없이 테이블 데이터, 텍스트, 이미지, 오디오까지 복잡한 모델 설정으로 혼합하여 사용할 수 있습니다.
-
풍부한 모델 내보내기 및 추적
Tensorboard, Comet ML, Weights & Biases, MLFlow, Aim Stack 등의 도구로 모든 시도와 메트릭을 자동으로 추적합니다.
-
멀티 GPU, 멀티 노드 클러스터로 학습 자동 확장
로컬 머신에서 클라우드로 코드 변경 없이 전환할 수 있습니다.
-
사전 학습된 Huggingface Transformers를 포함한 최신 모델의 로우코드 인터페이스
Ludwig는 Huggingface Transformers에서 제공하는 사전 학습된 모델과 네이티브로 통합됩니다. 사용자는 코드를 전혀 작성하지 않고도 방대한 최신 사전 학습 PyTorch 모델을 사용할 수 있습니다. 예를 들어, Ludwig로 BERT 기반 감성 분석 모델을 학습시키는 것은 다음과 같이 간단합니다:
ludwig train --dataset sst5 --config_str "{input_features: [{name: sentence, type: text, encoder: bert}], output_features: [{name: label, type: category}]}" -
AutoML을 위한 로우코드 인터페이스
Ludwig AutoML을 사용하면 데이터셋, 대상 컬럼, 시간 예산만 제공하여 학습된 모델을 얻을 수 있습니다.
auto_train_results = ludwig.automl.auto_train(dataset=my_dataset_df, target=target_column_name, time_limit_s=7200)
-
손쉬운 프로덕션화
Ludwig는 GPU를 포함한 딥러닝 모델 서빙을 쉽게 만들어 줍니다. 학습된 Ludwig 모델에 대한 REST API를 실행하세요.
ludwig serve --model_path=/path/to/model
Ludwig는 효율적인 Torchscript 번들로 모델 내보내기를 지원합니다.
ludwig export_torchscript --model_path=/path/to/model
- 개체명 인식 태깅
- 자연어 이해
- 기계 번역
- seq2seq를 통한 대화 모델링
- 감성 분석
- 시아미즈 네트워크를 이용한 원샷 학습
- 시각적 질의응답
- 음성 숫자 인식
- 화자 인증
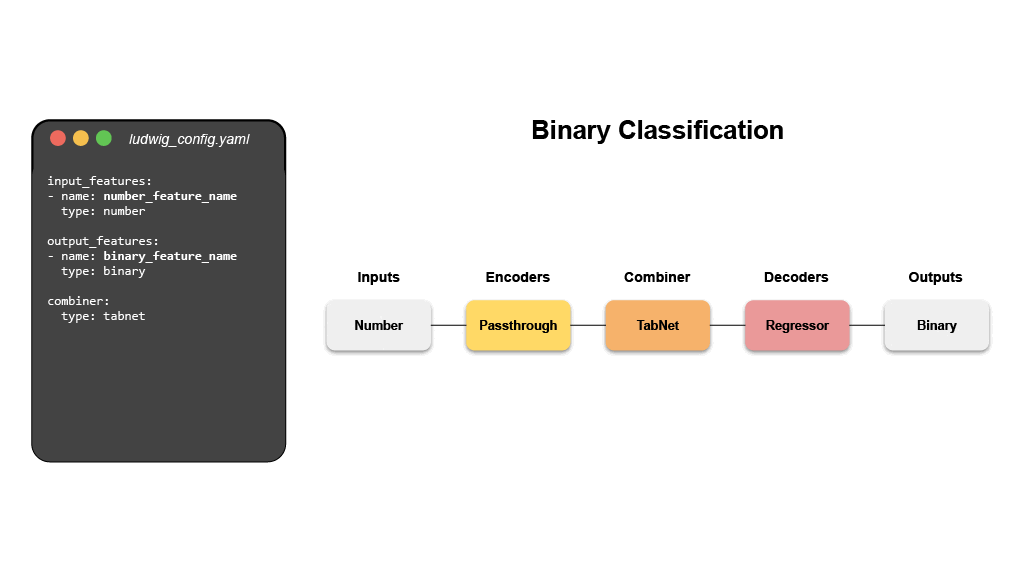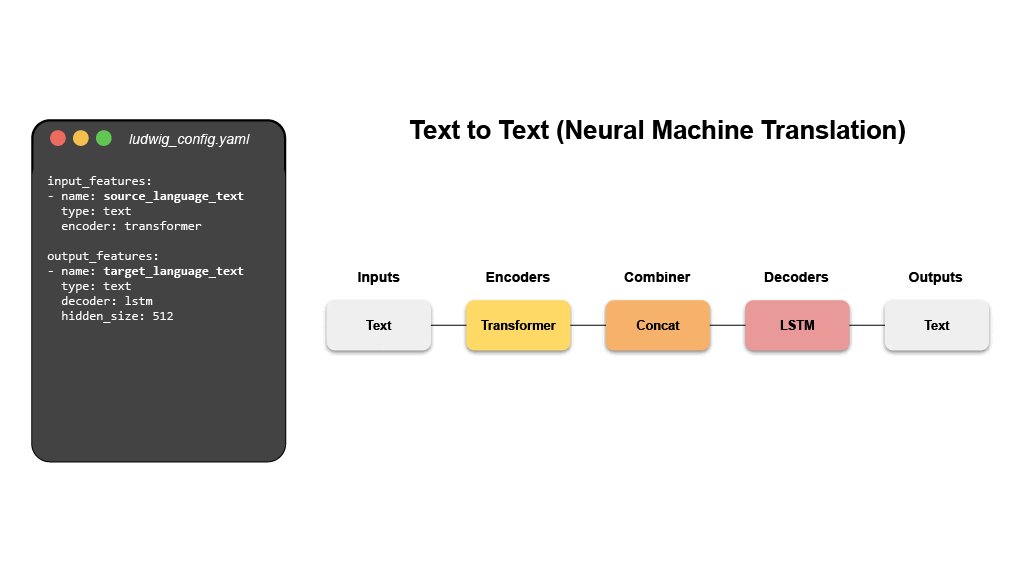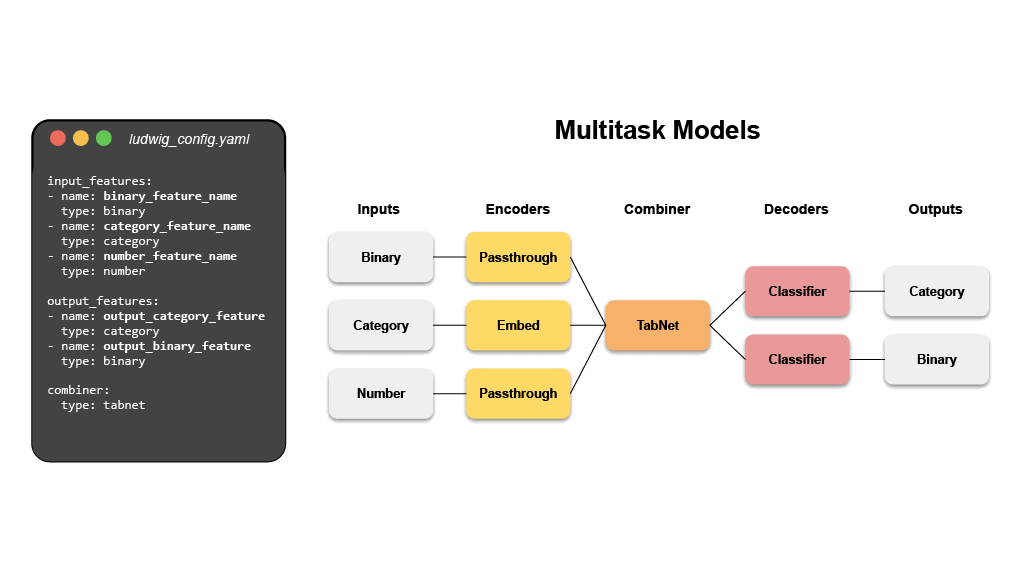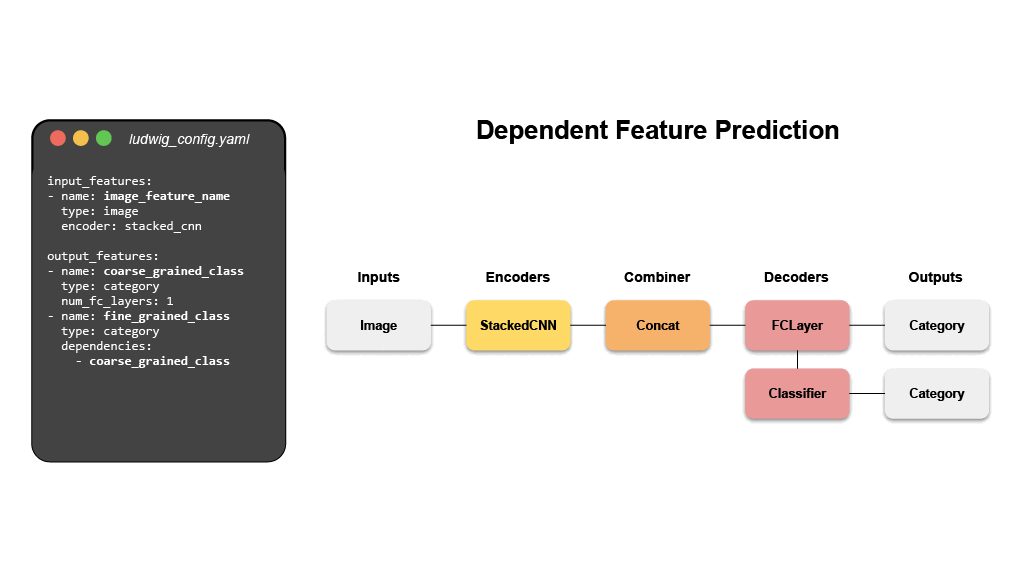
- 이진 분류 (타이타닉)
- 시계열 예측
- 시계열 예측 (날씨)
- 영화 평점 예측
- 다중 레이블 분류
- 멀티태스크 학습
- 단순 회귀: 연비 예측
- 사기 탐지
Ludwig, 선언적 ML, Ludwig의 SoTA 벤치마크에 대한 논문을 읽어보세요.
Ludwig의 작동 방식, 시작 가이드, 더 많은 예제를 확인하세요.
기여에 관심이 있으시거나, 질문, 의견, 공유하고 싶은 생각이 있으시거나, 최신 정보를 받고 싶으시다면 Discord 커뮤니티에 참여하시고 X에서 팔로우해 주세요!
Ludwig는 여러분과 같은 분들의 기여에 의존하는 활발하게 관리되는 오픈소스 프로젝트입니다. Ludwig를 모든 사람이 사용할 수 있는 더 접근 가능하고 기능이 풍부한 프레임워크로 만들기 위해 활발한 Ludwig 기여자 그룹에 참여하는 것을 고려해 주세요!